
How much memory do we fucking need?
2026-06-22

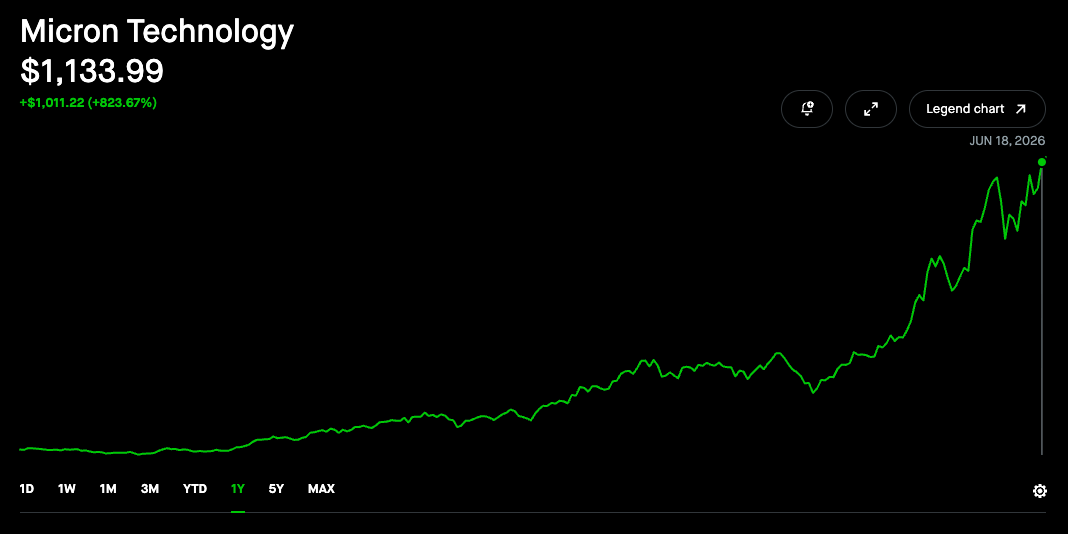
If you had bought $50K of MU 0.00%↑ in September of last year, it’d be worth $489,255 today. If you had bought the same amount of SK Hinyx Inc, it’d be worth $521,000. Either you don’t own these stocks and are thinking to yourself “Fuck, am I too late?”. Or, you own at least one of them and are asking yourself daily “Am I about to be the exit liquidity?”.
This essay makes the argument that memory stocks can still 10x from current valuations, if one’s reasoning is not rooted in the psychological constraints of historical performance and all-time highs. Instead, we conduct a pseudo-technical, bottoms-up analysis that demonstrates that the demand for memory is several magnitudes of order greater than what the world can currently produce.
A Single Chat Message
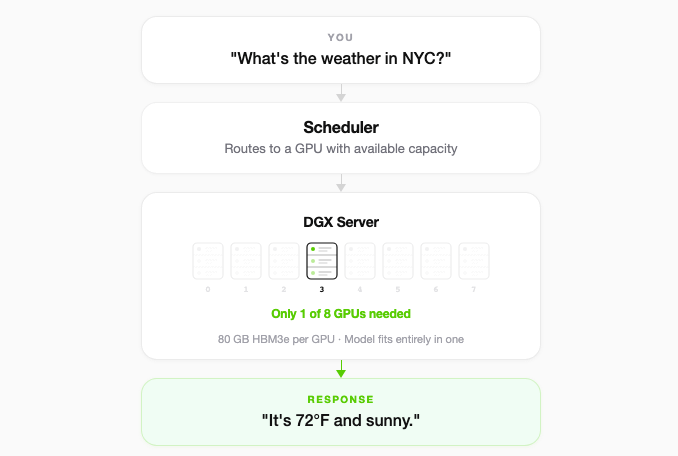
Let’s start off with the basics, which hopefully everyone is familiar with, and then we’ll work our way down to get a deeper understanding of how much memory is needed on a per-chat basis. When you send a message in ChatGPT, this is the rough outline of what happens underneath the hood. As your dopamine-addicted mind awaits a response from the appropriately named “Token Casino” [1], your message is tokenized, scheduled, and routed to an available GPU. At that point, the translated vector is run through billions of matrix multiplications and out comes the most likely next word. This is repeated over and over again, usually in pieces until the response is completed, i.e [“It’s 72F”, “and sunny.”].
If you’d like a more detailed understanding, the following article has a great breakdown: https://www.0xkato.xyz/how-llms-actually-work/
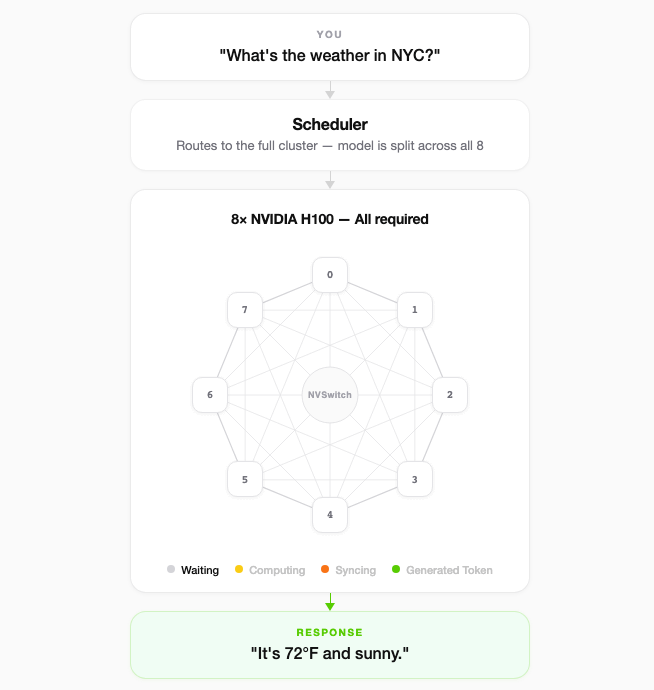
Now, smaller models (Llama 3.1-8B or Mistral-7B) can fit onto a single GPU, meaning there’s no cross-GPU communication required to generate a response. The singular GPU has a copy of all of the weights and all of the high-bandwidth memory (HBM) is localized on the server. But, frontier models, with billions, or even trillions, of parameters, need to be served with a group of GPU(s), often times known as a cluster. More specifically, it requires what’s called tensor parallelism [2], where the weight matrices are split across GPU(s) and every forward pass requires them to exchange intermediate activations over NVLink. This is mandatory, not optional. For simplicity, depicted below is an 8-GPU cluster serving a single request.
The Memory Budget
Each GPU ships with a fixed amount of high-bandwidth memory (HBM). This memory is soldered on to the chip and it is not expandable. For reference, the standard H100 SXM5 that sits inside every DGX server only has 80GB [3]. That’s it. Now, of course, newer generations push this limit higher, but there’s still a ceiling when it comes to how much memory a GPU has access to.
H100 SXM5: 80GB
H200: 141GB
B200: 192GB
Upcoming B300: 288GB
When most people think about memory, their mind jumps to model weights, which are the fixed set of parameters that define what a model knows. But, the other part of the equation is the Key-Value Cache, a per-session memory store that grows with every token generated. Importantly, model weights are fixed in size. But, the KV Cache scales linearly with the context length and becomes concerning when the # of concurrent sessions grows.
I introduce the concept of a “Session” here purposefully. For most people, a “Chat” is equivalent to a Session. But, in the world of agents, the vast majority of sessions are not controlled by or even visible to humans via a chat interface. Instead, they are programmed by software engineers, who are able to spin up and orchestrate thousands, if not hundreds of thousands of sessions in parallel. This is one of my main qualms when people try to anecdotally reason through how many GPU(s) or how much memory the world needs. They fixate on the # of chat sessions that they or their friends create. But, they remain oblivious to the # of sessions that their favorite products will run on behalf of and unbeknownst to them.
Now, let’s do some math with Llama 3.1-70B [4], which is a real model with published specifications. The calculation below shows that 1 token consumes 160KB of memory.
KV Cache Per Token = 2 x Layers x KV Heads x Head Dimensions x 1 Byte
= 2 x 80 x 8 x 128 x 1
= 163,840 Bytes
= 160KB Per Token
And if you extrapolate that out, a single session with 128K tokens of context requires ~20GB of memory. That’s just for one user. Four concurrent sessions at max context and you’ve already exhausted an entire H100.
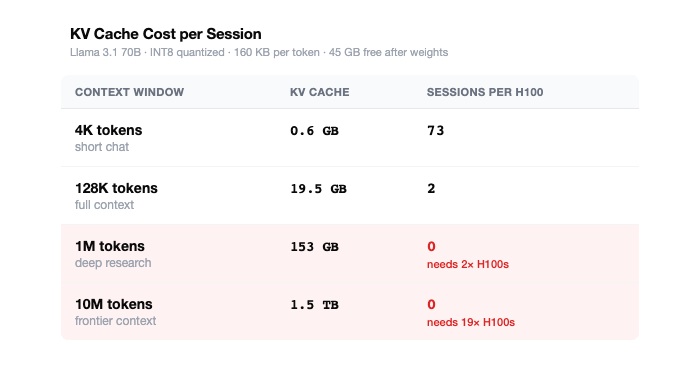
Now, frontier models, like Anthropic’s Opus-4.8 or Open AI’s GPT-5.5, are larger but the KV cache does not simply scale with the # of parameters. Instead, it scales with the model’s attention dimensions, which is typically 2-5x larger, meaning it can require 40-100GB of memory to serve a 128K token request. This is why every additional gigabyte of HBM matters and why memory suppliers like Micron and SK Hinyx can’t build this shit fast enough.
Not All Sessions Are Equal
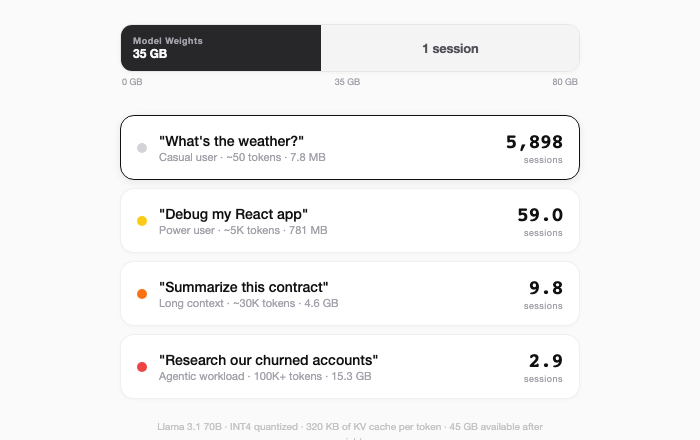
Not every session is a quick “What’s the weather” query in ChatGPT. And the distribution of complexity matters enormously when trying to calculate how much memory is needed.
A casual user asking a simple question? Well, it requires almost no memory and you can serve thousands of these requests on a single GPU. An indie developer debugging their React application? Well, that requires ~800MB of memory and now you’re only able to serve ~60 concurrent sessions. What about a lawyer uploading a 50-page contract that they need to redline? Well shit, that requires almost 5GB of memory to handle and you’re quickly down to 10 sessions on a single GPU.
Finally, there’s the agentic workload: the self-looping, context-consuming behemoth that can quickly get to 100K+ tokens, if not more. It turns out that these workloads, promised to us by Sam Altman and Jensen Huang, require a lot of memory. More importantly, this is where the world is moving and the types of sessions investors should anticipate.
The Agentic Effect
Here’s an example of an Agentic session. I’d encourage you to click the link & skim it, because most people are not that familiar with tool calling and they don’t have a great intuition for how quickly it can consume memory:
https://diagrams.thezeitgeistlabs.com/how-much-memory-do-we-need/agentic-session
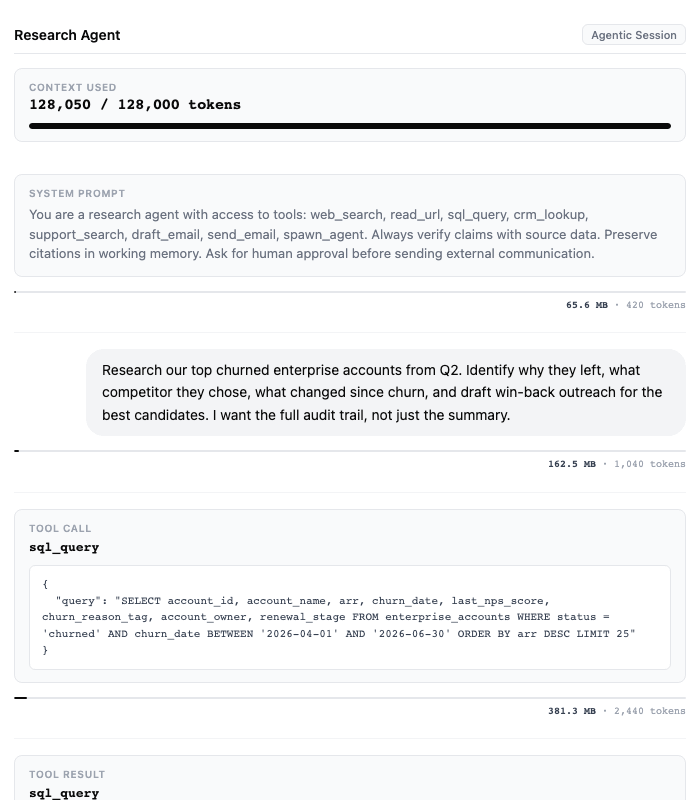
Look at how fast 100K tokens is needed for a relatively simple workflow that any AE or CSM might run numerous times per day. I don’t know about you, but it’s not that hard for me to envision every knowledge worker firing off dozens of these task, in parallel, over and over again for 8-10 hours a day.
Insatiable Demand
Humans are greedy fuckers. We get used to cool shit quickly. And when we get used to something, we want more. Headlines like this have already started popping up but they will only become more & more frequent (or we’ll get used to overspending headlines and stop publishing them).
Let’s look at the usage for a single knowledge worker. Memory isn’t consumed cumulatively, it’s allocated when a session starts and it’s freed when it ends. What matters is peak concurrent memory: how many sessions are live at the same time.
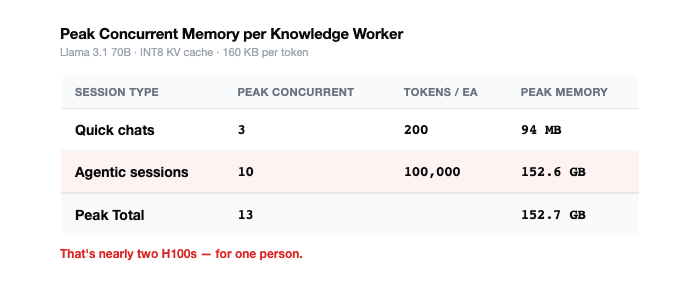
The quick chats are noise; the entire memory budget is dominated by agentic sessions. And a knowledge worker running ten concurrent agents at 100K tokens each needs ~152GB of memory to support that level of traffic. There are an estimated 250 million knowledge workers globally [6]. Multiply that by the # of concurrent agentic sessions each worker runs, and the memory demand doesn’t just grow, it explodes.
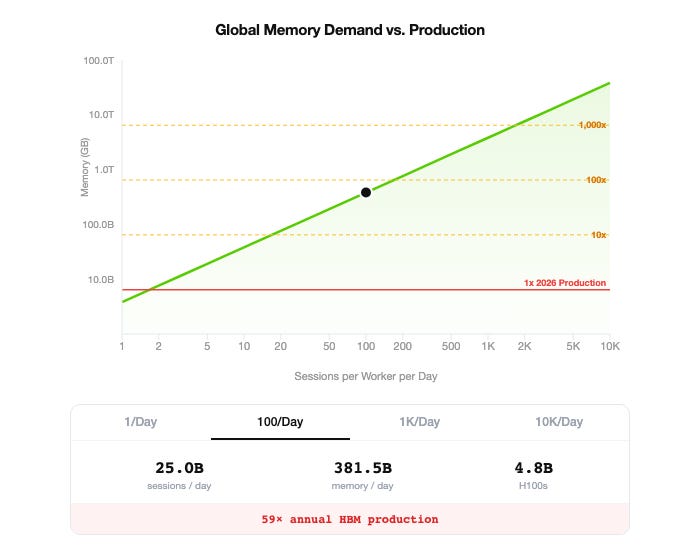
The Current State of Affairs
Based on research, this is our estimate on the current levels of HBM production.
These are estimates that are triangulated from: company bit-shipment disclosures, HBM/DRAM mix commentary, publicly reported HBM-dedicated capacity by vendor, company comments on sold-out supply and pricing/volume agreements, and external hard constraints such as wafer intensity and packaging capacity. The methodology is described in more detail within the Appendix.
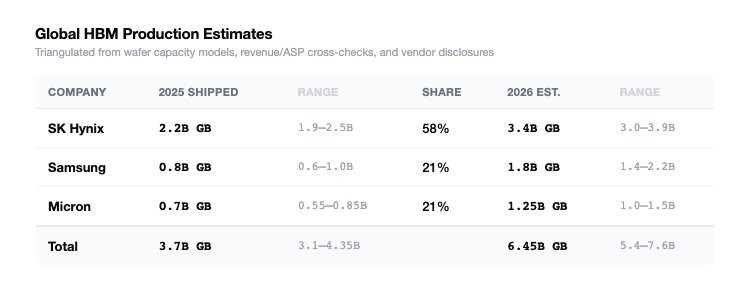
If you compare this table against the graphic above, at 100 agentic sessions per knowledge worker per day, the world needs 385 Billion Gigabytes of HMD to serve that level of traffic. Thats ~60x more than the amount that’s going to be produced in 2026.
Algorithmic Improvements
The 160KB/token math is a base case. It assumes multi-head attention on a mid-size open source model. Frontier models already use Grouped Query Attention (GQA) and Multi-Latent Attention, which can cut KV cache usage by 4-8x. And the optimization roadmap won’t stop there. More broadly, frontier AI labs are allocating significant engineering and research resources to lower memory usage during inference. China is GPU-constrained and scarcity breeds invocations: DeepSeek’s MLA architecture is a direct example of this.
So why does the thesis still hold? Because algorithmic improvements buy you constant factors: 4x, 8x, maybe 16 over the next few years. The demand side is still growing by 100-100x as agents replace chat, context windows expand from 128K to 10M tokens, and every knowledge worker goes from 0 → 100 in AI usage. The purpose of this essay is to give you the building blocks to do order-of-magnitude math yourself. Plug in your own assumptions about adoption rates and architectural improvements to see where you think HBM is headed.
Final Words
It turns out that we need a metric fuck ton of memory. Financial analysts are worriedly looking at historical performance or all-time highs as rationale for what to do next. They struggle to imagine a world where LLMs are not just helpful, but are intertwined in every aspect of daily life. In that world, memory is crucial and whatever companies produce it will achieve unprecedented amounts of revenue.
Appendix: HBM Supply Methodology
The estimates in “The Current State of Affairs” are derived from two independent methods, then triangulated against each other. Neither method alone is precise enough to narrow the range, but their overlap gives us confidence in the central estimates.
Method 1: Wafer Capacity → GB Output
Each HBM vendor operates a known number of wafer starts per month, reported by TrendForce and cross-referenced against company disclosures. We convert wafer starts to GB output using a conservative model:
Effective output per HBM wafer: 1.1–1.4 TB (HBM3E generation)
This is derived from:
Samsung HBM3E 12-high uses 24 Gb DRAM dies, delivering 36 GB per stack [19]
Micron HBM3E is an 8-high 24 GB stack with 50% higher monolithic die density [18]
Die size ~121 mm² (estimated), on a standard 300mm wafer
Conservative all-in haircut for wafer yield + stack/test losses
Consistent with Micron’s stated 3:1 trade ratio with DDR5 [9]
Capacity Data

Samsung’s 2025 effective average is far below nameplate capacity because its HBM ramp was severely back-end loaded. Q1 2025 was weak due to export controls, HBM bit shipments grew 30% QoQ in Q2 [22], and then surged mid-80% QoQ in Q3 [23]. SemiAnalysis also reported Samsung’s HBM yields lagged SK Hynix and Micron through mid-2025 [21].
Implied Output
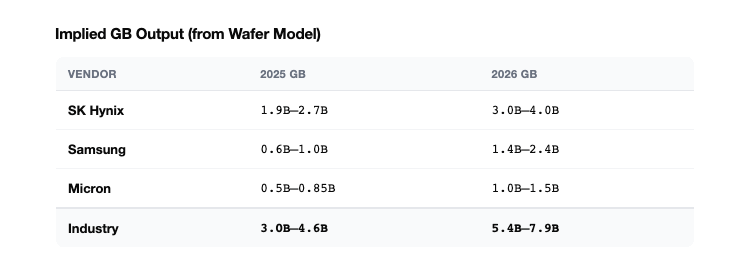
Method 2: Revenue ÷ ASP Cross-Check
Micron disclosed the 2025 HBM market TAM as ~$35B [9]. Bank of America estimates the 2026 HBM market at $54.6B [20]. Applying blended ASP estimates of $8–$11/GB (2025, HBM3E-heavy) and $10–$14/GB (2026, HBM4 mix shift):
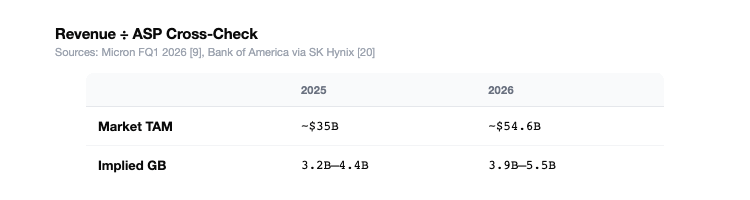
We then split by market share. As of Q1 2026, Counterpoint Research reports SK Hynix at 58%, Samsung at 21%, and Micron at 21% [16].
Micron-specific cross-check: Micron reported HBM revenue of nearly $2B in fiscal Q4 2025 alone [10]. This implies a full-year 2025 HBM revenue of ~$4.5B–$6B (the ramp was heavily back-loaded), which at $8–$11/GB gives 0.4B–0.75B GB — consistent with the wafer model’s 0.5B–0.85B range.
Triangulation
The two methods produce overlapping ranges for all three vendors. The central estimates are picked from the overlap:

Key Caveats
“Produced” ≈ “shipped” right now. All three vendors describe sold-out supply conditions. SK Hynix says HBM supply volumes are agreed roughly a year in advance [11]. Micron says price and volume are already set for all of calendar 2026 HBM supply [9]. Inventory swings are much less important than in commodity DRAM.
The largest uncertainty is effective GB per HBM wafer. Public yield and die-size data are incomplete. The ranges above use conservative assumptions, but vendor-grade yield disclosures would narrow them significantly.
2026 estimates assume no demand destruction. If a major customer cancels or delays orders, actual shipments could come in below projections — though current evidence (multi-year supply agreements, sold-out capacity) suggests this is unlikely.
References
[1] https://x.com/vral/article/2064067264991654236
[2] https://people.eecs.berkeley.edu/~matei/papers/2021/sc_megatron_lm.pdf
[3] https://resources.nvidia.com/en-us-gpu-resources/h100-datasheet-24306
[4] https://huggingface.co/meta-llama/Llama-3.1-70B
[5] https://platform.claude.com/docs/en/managed-agents/define-outcomes
[7] https://platform.claude.com/docs/en/managed-agents/define-outcomes
[8] https://ai.meta.com/blog/llama-4-multimodal-intelligence/
[9] Micron FQ1 2026 Prepared Remarks (Dec 17, 2025) — https://investors.micron.com/static-files/088991c5-a249-4f66-a0a6-258d9b66f3f9
[10] Micron FQ4 2025 Prepared Remarks (Sept 23, 2025) — https://investors.micron.com/static-files/5ea95475-639b-4cfc-91fd-b9b4a2bb5e63
[11] SK Hynix Q3 2025 Financial Results (Oct 29, 2025) — https://news.skhynix.com/sk-hynix-announces-3q25-financial-results/
[13] TrendForce — Samsung Reportedly Plans 50% HBM Capacity Surge (Dec 30, 2025) — https://www.trendforce.com/news/2025/12/30/news-samsung-reportedly-plans-50-hbm-capacity-surge-in-2026-spotlight-on-hbm4/
[14] TrendForce — Micron Reveals Three Culprits Behind Memory Crunch (Dec 18, 2025) — https://www.trendforce.com/news/2025/12/18/news-micron-reveals-three-culprits-behind-memory-crunch-and-why-it-wont-ease-soon/
[16] Counterpoint Research — Global DRAM and HBM Market Share Q1 2026 — https://counterpointresearch.com/en/insights/global-dram-and-hbm-market-share
[18] Micron HBM3E Product Page — https://www.micron.com/products/memory/hbm/hbm3e
[19] TechInsights — Samsung 12Hi HBM from AMD MI350X Floorplan Analysis — https://www.techinsights.com/blog/samsung-12hi-hbm-amd-mi350x-floorplan-analysis
[20] SK Hynix 2026 Market Outlook (cites Bank of America HBM TAM estimate) — https://news.skhynix.com/2026-market-outlook-focus-on-the-hbm-led-memory-supercycle/
[21] SemiAnalysis — Scaling the Memory Wall: The Rise and Roadmap of HBM —
[22] Samsung Q2 2025 Earnings Call — https://www.alphaspread.com/security/krx/005930/investor-relations/earnings-call/q2-2025
[23] Samsung Q3 2025 Earnings Call — https://www.alphaspread.com/security/krx/005930/investor-relations/earnings-call/q3-2025
[24] McKinsey Global Institute — Jobs lost, jobs gained: Workforce transitions in a time of automation (2017) — https://www.mckinsey.com/featured-insights/future-of-work/jobs-lost-jobs-gained-what-the-future-of-work-will-mean-for-jobs-skills-and-wages